Example usage of archR on simulated DNA sequences
Sarvesh Nikumbh
2021-07-01
Source:vignettes/archR.Rmd
archR.RmdIntroduction
archR is a non-negative matrix factorization (NMF)-based unsupervised learning approach for identifying different core promoter sequence architectures. archR implements an algorithm based on chunking and iterative processing. While matrix factorization-based applications are known to scale poorly for large amounts of data, archR’s algorithm enables scalable processing of large number of sequences. A notable advantage of archR is that the sequence motifs – the lengths and positional specificities of individual motifs, and complex inter-relationships where multiple motifs are at play in tandem, all are simultaneously inferred from the data. To our knowledge, this is a novel application of NMF on biological sequence data capable of simultaneously discovering the sequence motifs and their positions. For a more detailed discussion, see preprint/publication [TODO: link here].
This vignette demonstrates archR’s usage with the help of a synthetic DNA sequences data set. Please refer to the paper (TODO: cite paper/preprint) for a detailed description of archR’s algorithm. The paper also discusses the various parameters and their settings. For completeness, the following section gives a brief overview of the algorithm.
archR’s algorithm
archR implements a chunking-based iterative procedure. Below is a schematic of archR’s algorithm.
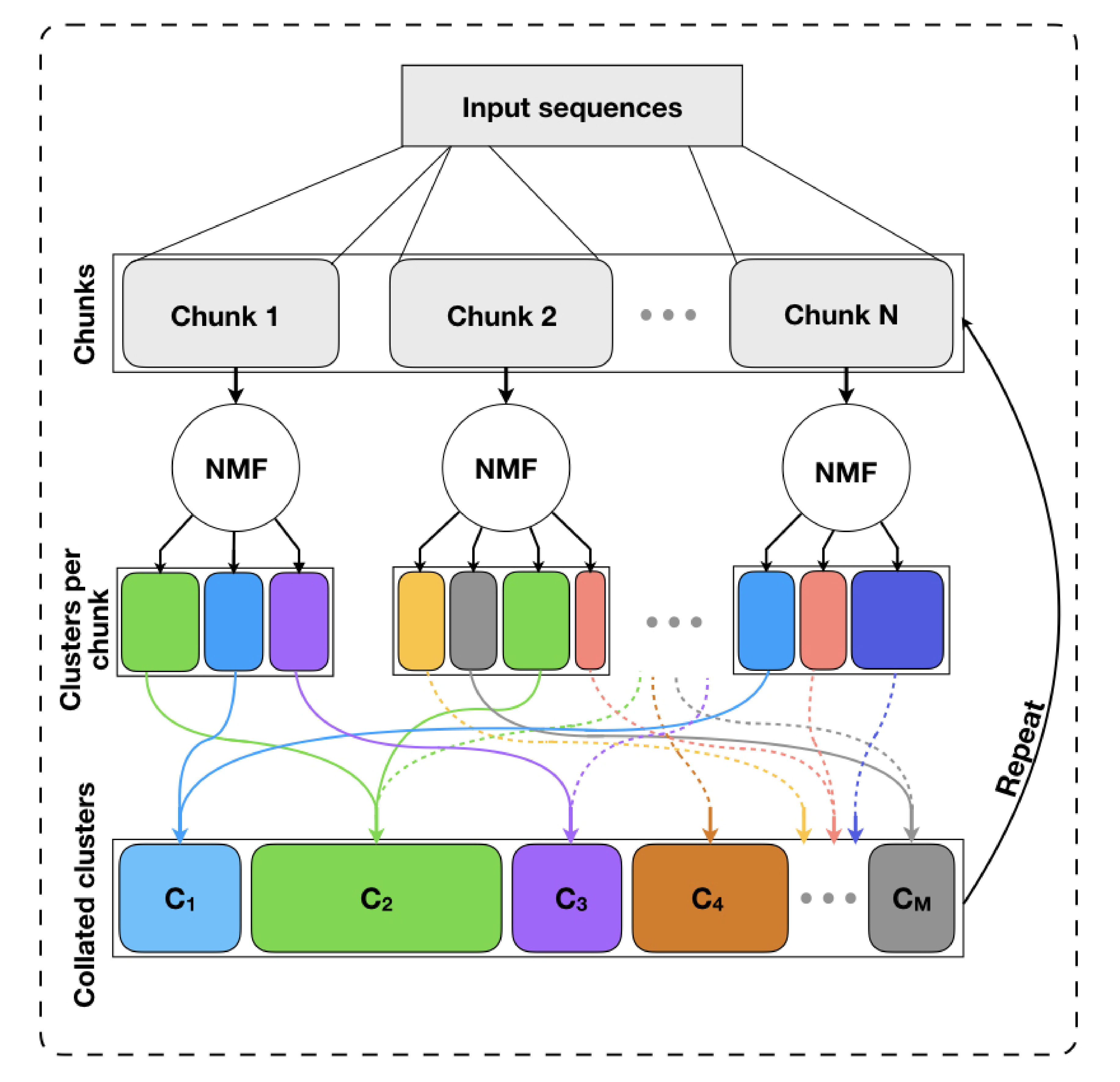
Further details to follow.
Installation
archR is currently made available via GitHub, thus, you can use the following procedure for installing archR.
if (!requireNamespace("remotes", quietly = TRUE)) {
install.packages("remotes")
}
remotes::install_github("snikumbh/archR")
In case of any errors, please consider looking up: https://github.com/snikumbh/archR. If none of the already noted points with regards to troubleshooting archR’s installation help, please file a new issue.
Working with archR
# Load archR
library(archR)
library(Biostrings, quietly = TRUE)
#>
#> Attaching package: 'BiocGenerics'
#> The following objects are masked from 'package:parallel':
#>
#> clusterApply, clusterApplyLB, clusterCall, clusterEvalQ,
#> clusterExport, clusterMap, parApply, parCapply, parLapply,
#> parLapplyLB, parRapply, parSapply, parSapplyLB
#> The following objects are masked from 'package:stats':
#>
#> IQR, mad, sd, var, xtabs
#> The following objects are masked from 'package:base':
#>
#> anyDuplicated, append, as.data.frame, basename, cbind, colnames,
#> dirname, do.call, duplicated, eval, evalq, Filter, Find, get, grep,
#> grepl, intersect, is.unsorted, lapply, Map, mapply, match, mget,
#> order, paste, pmax, pmax.int, pmin, pmin.int, Position, rank,
#> rbind, Reduce, rownames, sapply, setdiff, sort, table, tapply,
#> union, unique, unsplit, which.max, which.min
#>
#> Attaching package: 'S4Vectors'
#> The following objects are masked from 'package:base':
#>
#> expand.grid, I, unname
#>
#> Attaching package: 'Biostrings'
#> The following object is masked from 'package:base':
#>
#> strsplit
# Set seed for reproducibility
set.seed(1234)Synthetic data explained
In order to demonstrate the efficacy of archR, we use archR to cluster DNA sequences in a synthetic data set which was generated as follows. A set of 200 simulated DNA sequences was generated, each 100 nucleotides long and with uniform probability for all nucleotides. These sequences have four clusters in them, each with 50 sequences. The profiles of the four clusters are:
| Cluster | Characteristic Motifs | Motif Occurrence Position | #Sequences |
|---|---|---|---|
| A | Dinucleotide repeat AT
|
every 10 nt | 50 |
| B | GATTACA |
40 | 50 |
GAGAG |
60 | ||
| C | GAGAG |
60 | 50 |
| D | GAGAG |
80 | 50 |
TCAT |
40 |
All the motifs across the clusters were planted with a mutation rate of 0.
Input and feature representation
We use one-hot encoding to represent the dinucleotide profiles of each sequence in the data set. archR provides functions to read input from (a) a FASTA file, and (b) Biostrings::DNAStringSet object.
Reading input as FASTA file
The function archR::prepare_data_from_FASTA() enables one-hot-encoding the DNA sequences in the given FASTA file. The one-hot-encoded sequences are returned as a sparse matrix with as many columns as the number of sequences in the FASTA file and (sequence length x \(4^{2}\)) rows when dinucleotide profiles is selected. The number of rows will be (sequence length x \(4\)) when mononucleotide profiles is selected. See the sinuc_or_dinuc argument.
Upon setting the logical argument rawSeq to TRUE, the function returns the raw sequences as a Biostrings::DNAStringSet object, with FALSE it returns the column-wise one-hot encoded representation as noted above. When raw_seq is TRUE, sinuc_or_dinuc argument is ignored.
# Creation of one-hot encoded data matrix from FASTA file
inputFname <- system.file("extdata", "example_data.fa",
package = "archR",
mustWork = TRUE)
# Specifying `dinuc` generates dinucleotide features
inputSeqsMat <- archR::prepare_data_from_FASTA(fasta_fname = inputFname,
sinuc_or_dinuc = "dinuc")
#> Sequences OK,
#> Read 200 sequences
#> Generating dinucleotide profiles
inputSeqsRaw <- archR::prepare_data_from_FASTA(fasta_fname = inputFname,
raw_seq = TRUE)
nSeqs <- length(inputSeqsRaw)
positions <- seq(1, Biostrings::width(inputSeqsRaw[1]))Reading input as a DNAStringSet object
If you already have a Biostrings::DNAStringSet object, you can use the get_one_hot_encoded_seqs() function which directly accepts a DNAStringSet object.
# Creation of one-hot encoded data matrix from a DNAStringSet object
inputSeqs_direct <- archR::get_one_hot_encoded_seqs(seqs = inputSeqsRaw,
sinuc_or_dinuc = "dinuc")
#> Generating dinucleotide profiles
identical(inputSeqs_direct, inputSeqsMat)
#> [1] TRUEVisualize input sequences as an image
# Visualize the sequences in a image matrix where the DNA bases are
# assigned fixed colors
archR::viz_seqs_acgt_mat_from_seqs(as.character(inputSeqsRaw),
pos_lab = positions, save_fname = NULL)
Calling archR
Setup archR configuration as follows.
# Set archR configuration
archRconfig <- archR::archR_set_config(
parallelize = TRUE,
n_cores = 2,
n_runs = 100,
k_min = 1,
k_max = 20,
mod_sel_type = "stability",
bound = 10^-6,
chunk_size = 100,
result_aggl = "ward.D",
result_dist = "euclid",
flags = list(debug = FALSE, time = TRUE, verbose = TRUE,
plot = FALSE)
)Once the configuration is setup, call the archR::archR function with user-specified iterations.
# Call/Run archR
archRresult <- archR::archR(config = archRconfig,
seqs_ohe_mat = inputSeqsMat,
seqs_raw = inputSeqsRaw,
seqs_pos = positions,
total_itr = 2,
set_ocollation = c(TRUE, FALSE))
#> ── Setting up ──────────────────────────────────────────────────────────────────
#> ℹ Parallelization: 2 cores
#> ℹ Model selection by factor stability
#> ℹ Bound: 1e-06
#>
#> ── Iteration 1 of 2 [1 chunk] ──────────────────────────────────────────────────
#>
#> ── Outer chunk 1 of 1 [Size: 200] ──
#>
#> ── Inner chunk 1 of 2 [Size: 100]
#> Checking K = 2
#> Checking K = 3
#> Checking K = 4
#> Checking K = 5
#> ℹ Best K for this chunk: 4
#> ℹ Adjusting for overfitting, fetched 3 clusters
#>
#> ── Inner chunk 2 of 2 [Size: 100]
#> Checking K = 2
#> Checking K = 3
#> Checking K = 4
#> Checking K = 5
#> ℹ Best K for this chunk: 4
#> ✔ 1 of 1 outer chunk complete
#> ✔ 1 of 2 iterations complete
#> → Iteration 1 completed: 59.2s
#> → Time ellapsed since start: 59.3s
#>
#> ── Iteration 2 of 2 [4 chunks] ─────────────────────────────────────────────────
#>
#> ── Outer chunk 1 of 4 [Size: 50] ──
#>
#> ── Inner chunk 1 of 1 [Size: 50]
#> Checking K = 2
#> ℹ Best K for this chunk: 1
#> ✔ 1 of 4 outer chunks complete
#>
#> ── Outer chunk 2 of 4 [Size: 70] ──
#>
#> ── Inner chunk 1 of 1 [Size: 70]
#> Checking K = 2
#> Checking K = 3
#> ℹ Best K for this chunk: 2
#> ✔ 2 of 4 outer chunks complete
#>
#> ── Outer chunk 3 of 4 [Size: 29] ──
#>
#> ── Inner chunk 1 of 1 [Size: 29]
#> Checking K = 2
#> ℹ Best K for this chunk: 1
#> ✔ 3 of 4 outer chunks complete
#>
#> ── Outer chunk 4 of 4 [Size: 51] ──
#>
#> ── Inner chunk 1 of 1 [Size: 51]
#> Checking K = 2
#> ℹ Best K for this chunk: 1
#> ✔ 4 of 4 outer chunks complete
#> ✔ 2 of 2 iterations complete
#> → Iteration 2 completed: 53.4s
#> → Time ellapsed since start: 1m 52.7s
#> ── archR exiting 1m 52.7s ──────────────────────────────────────────────────────Understanding the result object from archR
In the version 0.1.8, archR naively returns a result object which is a nested list of seven elements. These include: - the sequence cluster labels per iteration [seqsClustLabels]; - the collection of NMF basis vectors per iteration [clustBasisVectors]: each is a list of two elements nBasisVectors and basisVectors; - the clustering solution, [clustSol], which is obtained upon combining raw clusters from the last iteration of archR. This element stores the clustering of NMF basis vectors [basisVectorsClust] and the sequence clusters [clusters]; - the raw sequences provided [rawSeqs]; - if timeFlag is set, timing information (in minutes) per iteration [timeInfo]; - the configuration setting [config]; and - the call itself [call].
NMF basis vectors
archR stores the NMF basis vectors corresponding to each cluster in every iteration in the variable clustBasisVectors. clustBasisVectors is a numbered list corresponding to the number of iterations performed. This is then again a list holding two pieces of information: the number of basis vectors (nBasisVectors) and the basis vectors (basisVectors).
# Basis vectors at iteration 2
archR::get_clBasVec_k(archRresult, iter=2)
#> [1] 5
i2_bv <- archR::get_clBasVec_m(archRresult, iter=2)
dim(i2_bv)
#> [1] 1600 5
head(i2_bv)
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 0.05168607 0.07646511 0.05101696 0.08471968 0.12920686
#> [2,] 0.02486037 0.07603933 0.09368281 0.04243838 0.10288363
#> [3,] 0.05076204 0.04942229 0.04745960 0.04243838 0.07754562
#> [4,] 0.09945618 0.04225726 0.11945756 0.03847347 0.05154964
#> [5,] 0.07484865 0.09133385 0.17064509 0.04028088 0.09605441
#> [6,] 0.05051104 0.09435299 0.14381388 0.04232253 0.02514596The NMF basis vectors can be visualized as a heatmap and/or sequence logo using [https://snikumbh.github.io/archR/reference/viz_bas_vec_heatmap_seqlogo.html] (viz_bas_vec_heat_seqlogo) function.
Basis vectors at iteration 1
archR::viz_bas_vec_heatmap_seqlogo(feat_mat = get_clBasVec_m(archRresult, 1),
method = "bits", sinuc_or_dinuc = "dinuc")
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.
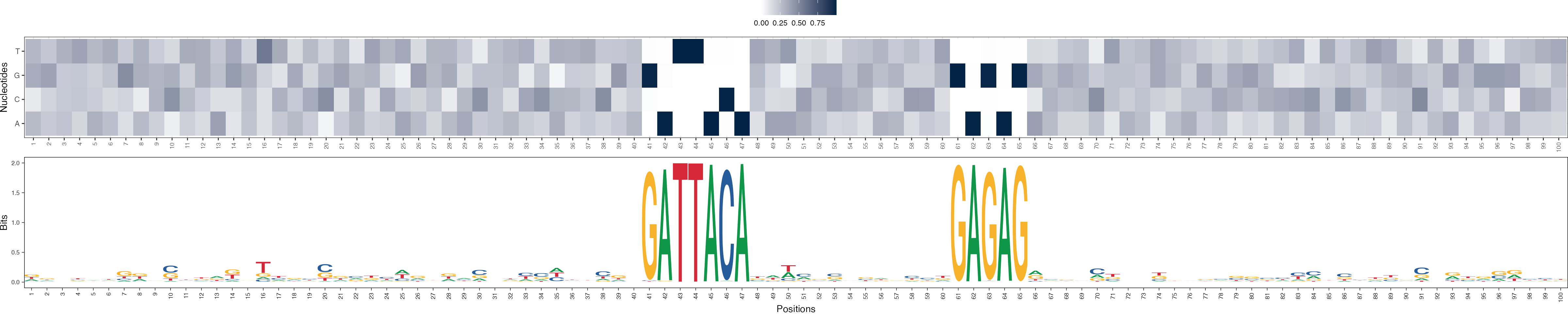
Basis vectors at iteration 2
archR::viz_bas_vec_heatmap_seqlogo(feat_mat = get_clBasVec_m(archRresult, 2),
method = "bits", sinuc_or_dinuc = "dinuc")
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.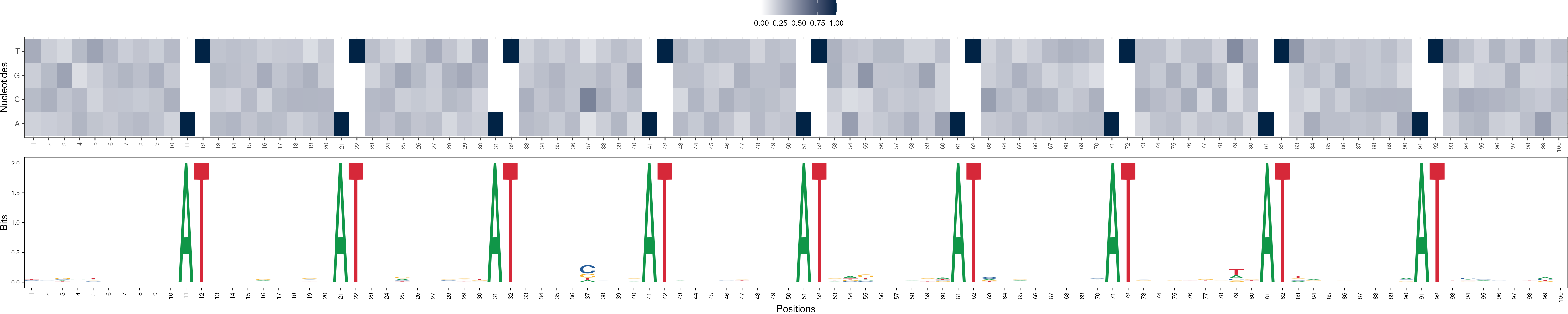
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.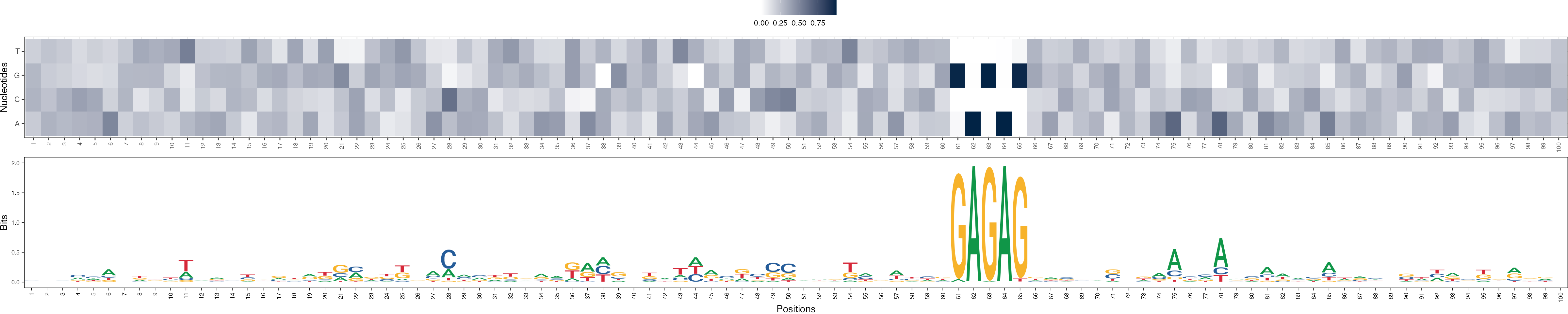
#> Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
#> "none")` instead.
#> Scale for 'x' is already present. Adding another scale for 'x', which will
#> replace the existing scale.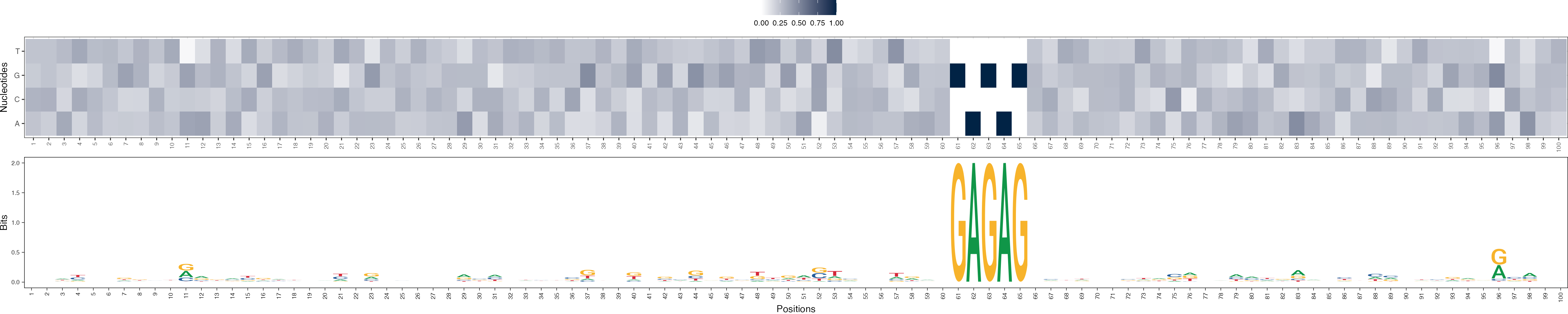

Visualize sequences by clusters
The clustered output from archR can again be visualized as a matrix. Use the https://snikumbh.github.io/archR/reference/seqs_str.html function to fetch sequences by clusters at any iteration and call archR::viz_seqs_as_acgt_mat_from_seqs as shown.
archR::viz_seqs_acgt_mat_from_seqs(seqs_str(archRresult, iter = 1, ord = TRUE),
pos_lab = positions)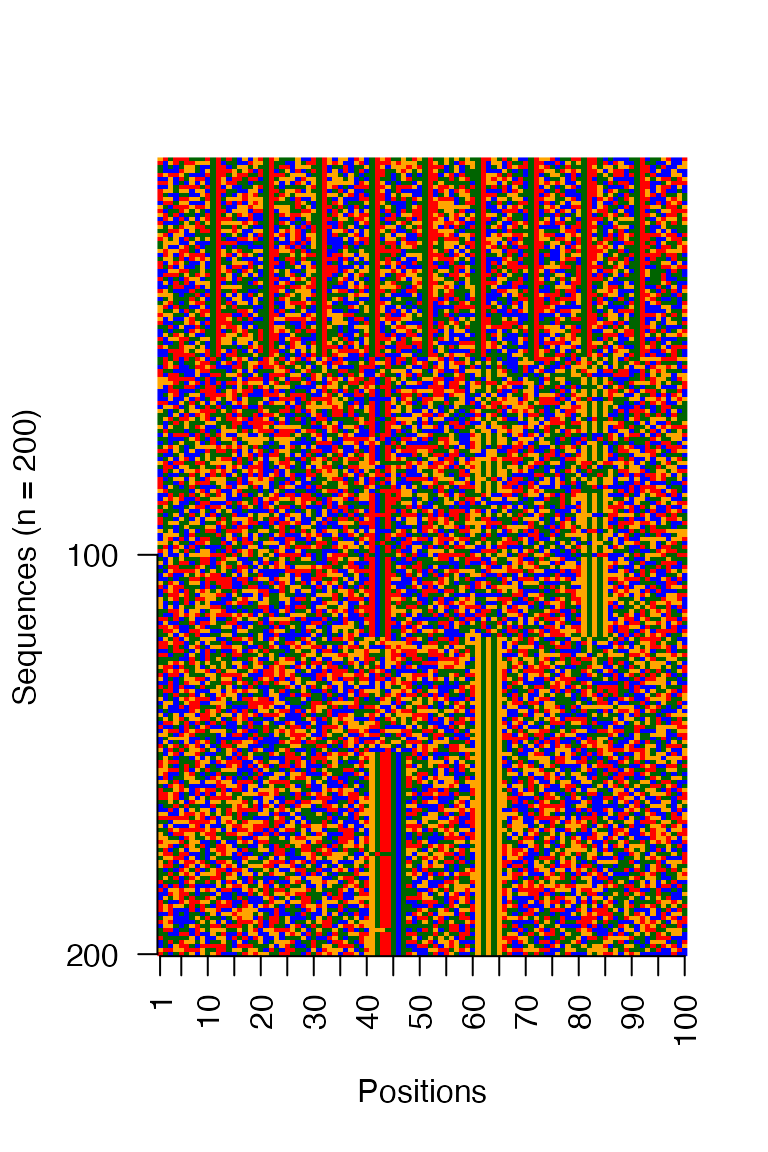
Figure: Clusters at iteration 1
archR::viz_seqs_acgt_mat_from_seqs(seqs_str(archRresult, iter = 2, ord = TRUE),
pos_lab = positions)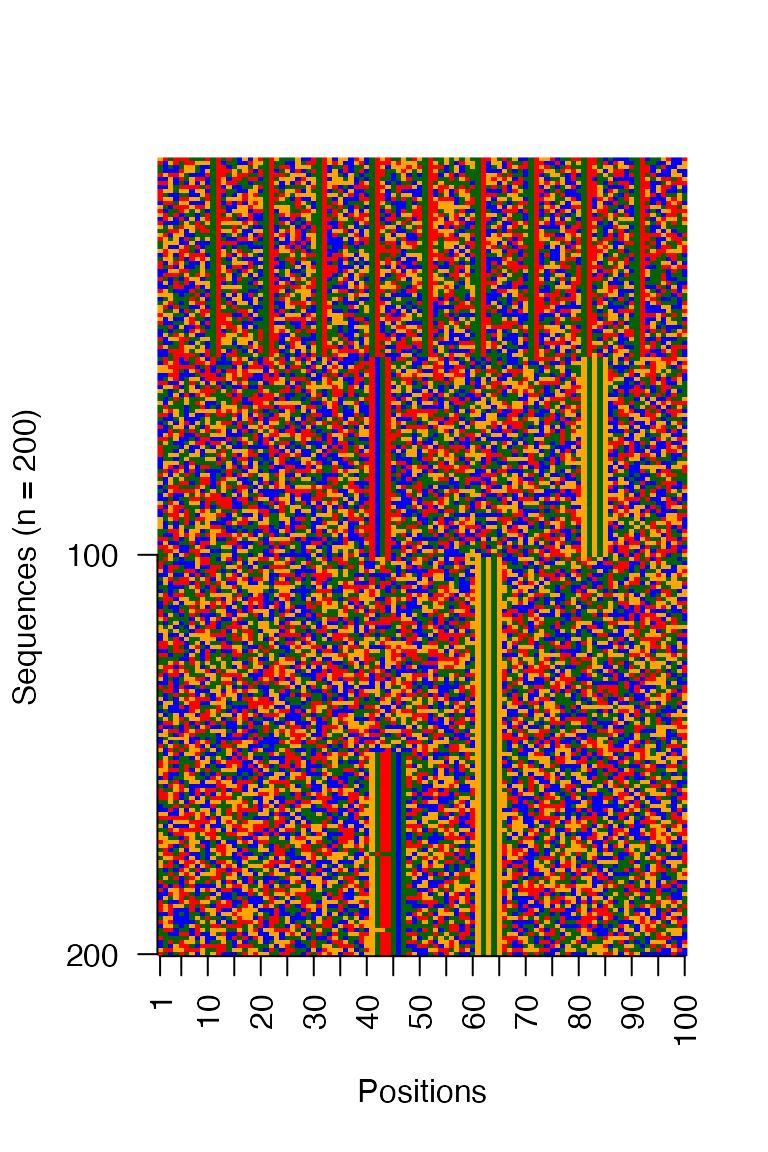
Figure: Clusters at iteration 2
Conclusion
archR can detect de novo sequence features and simultaneously identify the complex interactions of different features together with their positional specificities.
Note that the sequence architectures identified by archR have no limitations due to the size of the motifs or gaps in them, distance between motifs, compositional and positional variations in the individual motifs and their effects on the complex interactions, and number of motifs involved in any interaction.
Session Info
sessionInfo()
#> R version 4.1.0 (2021-05-18)
#> Platform: x86_64-apple-darwin17.0 (64-bit)
#> Running under: macOS Catalina 10.15.7
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> attached base packages:
#> [1] stats4 parallel stats graphics grDevices utils datasets
#> [8] methods base
#>
#> other attached packages:
#> [1] Biostrings_2.60.1 GenomeInfoDb_1.28.0 XVector_0.32.0
#> [4] IRanges_2.26.0 S4Vectors_0.30.0 BiocGenerics_0.38.0
#> [7] archR_0.1.8
#>
#> loaded via a namespace (and not attached):
#> [1] Rcpp_1.0.6 lattice_0.20-44 prettyunits_1.1.1
#> [4] ggseqlogo_0.1 rprojroot_2.0.2 digest_0.6.27
#> [7] utf8_1.2.1 R6_2.5.0 plyr_1.8.6
#> [10] evaluate_0.14 ggplot2_3.3.5 highr_0.9
#> [13] pillar_1.6.1 zlibbioc_1.38.0 rlang_0.4.11
#> [16] jquerylib_0.1.4 Matrix_1.3-3 rmarkdown_2.9
#> [19] pkgdown_1.6.1 labeling_0.4.2 textshaping_0.3.5
#> [22] desc_1.3.0 stringr_1.4.0 RCurl_1.98-1.3
#> [25] munsell_0.5.0 compiler_4.1.0 xfun_0.24
#> [28] pkgconfig_2.0.3 systemfonts_1.0.2 htmltools_0.5.1.1
#> [31] tibble_3.1.2 GenomeInfoDbData_1.2.6 matrixStats_0.59.0
#> [34] fansi_0.5.0 crayon_1.4.1 bitops_1.0-7
#> [37] grid_4.1.0 jsonlite_1.7.2 gtable_0.3.0
#> [40] lifecycle_1.0.0 magrittr_2.0.1 scales_1.1.1
#> [43] cli_3.0.0 stringi_1.6.2 cachem_1.0.5
#> [46] farver_2.1.0 reshape2_1.4.4 fs_1.5.0
#> [49] bslib_0.2.5.1 ellipsis_0.3.2 ragg_1.1.3
#> [52] vctrs_0.3.8 cowplot_1.1.1 tools_4.1.0
#> [55] glue_1.4.2 fastmap_1.1.0 yaml_2.2.1
#> [58] colorspace_2.0-2 cluster_2.1.2 memoise_2.0.0
#> [61] knitr_1.33 sass_0.4.0